很多人以为,大模型变差,就是模型“降智”了。
但智谱这次公开的一份技术报告,把事情讲得更复杂,也更真实。
GLM-5最近在一些 Coding Agent 任务里,被用户反馈出现乱码、复读、生僻字。用户第一反应很正常:模型是不是变笨了?
可工程师最后查出来的答案是:不是模型突然变笨,而是后台推理系统在高并发下出了问题。
这句话翻译成人话就是:
AI的大脑没坏,是负责传话和记忆的服务器没配合好。

用户看到的是“变傻”,工程师看到的是“复现不了”
事情一开始很像普通产品投诉。
用户发现,GLM-5在复杂编程任务里,有时会输出乱码,有时会不停重复一句话,有时还会冒出一些奇怪的生僻字。
这类表现很像大家常说的“AI降智”。
但智谱团队做了一件很关键的事:他们没有直接承认“模型变差了”,而是先把用户反馈的问题拿到本地反复跑。
结果很尴尬:跑了数百遍,复现不出来。
这说明一个问题:如果是模型本身有缺陷,它应该更稳定地出错。比如同一个输入,每次都容易回答错。
但现在不是。
本地没问题,线上才出问题。那就说明,问题很可能不在模型参数,而在生产环境。
后来他们模拟线上高负载场景,终于复现了异常:大约每一万次请求里,会出现3到5次异常。这个频率不高,但对每天数亿次调用的系统来说,已经足够明显。智谱官方报告也提到,这些异常主要出现在高并发、长上下文的 Coding Agent 场景里,而不是普通聊天场景。

真正的问题:两台服务器之间没对齐
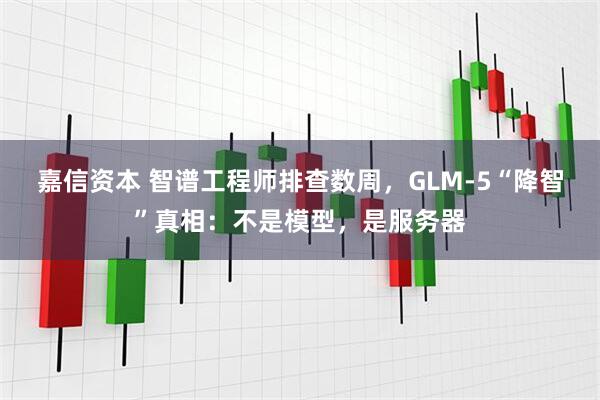
这里需要先解释一个概念:PD分离架构。
不用被名字吓到。
大模型回答问题,通常分两步。
第一步叫 Prefill,可以理解为“读题”。模型要先读完你的问题、代码、上下文,建立理解。
第二步叫 Decode,可以理解为“写答案”。模型开始一个字一个字往外生成。
为了提高效率,很多系统会把这两步拆开,让不同服务器或不同GPU分别负责。
这就像餐厅后厨:一个人负责备菜,一个人负责炒菜。理论上效率更高,但前提是两个人配合得上。
GLM-5这次的问题,就出在“配合”上。
模型推理过程中会用到一个东西,叫 KV Cache。你可以把它理解成模型的“临时记忆”。它记录前面已经读过、算过的信息,后面生成答案时就不用全部重新算。
一个请求结束后,这块临时记忆会被回收,给下一个请求继续用。
问题来了:在高并发场景下,有时系统以为上一轮已经写完,可以回收了。但实际上,另一边还在往里面写。
于是下一位用户的请求,拿到了一块被污染的“临时记忆”。
模型就在这块混乱的记忆上继续生成,结果自然可能乱码、复读、冒出奇怪字符。
这不是模型变笨。
这是两台服务器之间,有一件事没有人协调好。
智谱报告里还提到另一个问题:HiCache加载流水线缺少同步约束,也会导致系统在数据还没准备好时就开始读取。也就是说,这不是一个单点小Bug,而是长上下文、高并发、大规模推理下暴露出来的一组系统工程问题。
最巧妙的地方:加速工具变成了报警器
这份报告里最有意思的,不只是Bug本身,而是智谱怎么发现它。
他们用到了一个叫 投机采样 的指标。
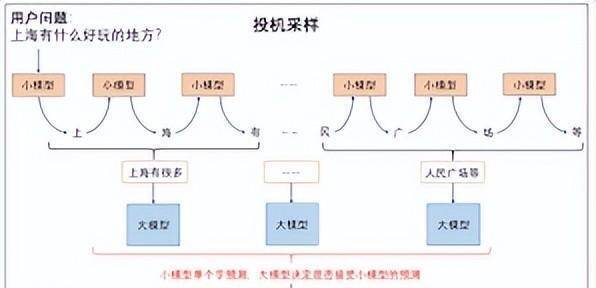
这个词也不用复杂解释。
投机采样可以理解为:让一个小模型先猜答案,大模型再检查。猜对了,就加速;猜错了,大模型纠正。
正常情况下,小模型猜中的比例会比较稳定。
但当KV Cache被污染后,这个比例会突然变得很怪。
如果出现乱码、生僻字,小模型猜的东西大模型几乎都不接受,接受率会很低。
如果出现复读,大模型反而可能陷入一种奇怪的高置信重复,接受率会异常偏高。
也就是说,投机采样本来是一个“加速器”,现在被智谱工程师拿来当“报警器”。
系统一旦发现接受率异常,就可以提前中止输出,重新排队,避免把乱码结果直接发给用户。
这个思路很有价值。
因为未来大模型不是只看“回答得聪不聪明”,还要看系统能不能在回答出错之前,自己发现不对劲。
修完这个Bug,又发现新瓶颈
智谱修复KV Cache竞态问题后,异常输出率从约万分之十几,降到万分之三以下。这个结果多家报道和智谱官方内容都提到了。
但工程世界就是这样:一个问题解决了,下一个瓶颈马上冒出来。
这次新的瓶颈在 Prefill,也就是“读题”阶段。
因为 Coding Agent 的任务越来越长。它不是简单问一句“今天吃什么”,而是可能把一整个代码仓库、多个文件、运行日志、报错信息全部塞给模型。
上下文越长,模型读题越累。
智谱的解法叫 LayerSplit。
简单说,就是不要让每张GPU都保存完整的KV Cache,而是让不同GPU只保存一部分层,需要计算时再协作汇总。

这样可以降低单张GPU的显存压力。
报告显示,在40K到120K上下文长度范围内,LayerSplit让系统吞吐提升了10%到132%,而且上下文越长,提升越明显。
这说明一件事:大模型的竞争,已经不只是“谁的模型参数更强”,还包括“谁能把模型稳定、便宜、高速地跑起来”。
这份报告真正重要的地方:敢公开讲事故
我觉得这件事最值得关注的,不是GLM-5出了Bug。
任何大规模系统都会出Bug。
真正重要的是:智谱把这个过程公开讲出来了。
这在国内AI公司里并不常见。
很多公司遇到问题,第一反应是压低声音,少说,别让用户知道。因为担心影响品牌,担心外界质疑技术能力。
但从云计算行业看,公开事故复盘本来就是成熟工程文化的一部分。AWS有公开的Post-Event Summaries,会说明影响范围、原因和后续措施;Google也长期强调事后复盘和无责复盘文化。
所以智谱这次报告释放出的信号是:
中国AI公司正在从模型竞赛,进入系统工程竞赛。
以前大家比的是榜单、参数、评测分数。
以后还要比稳定性、吞吐量、异常检测、故障复盘、工程透明度。
因为用户真正用AI干活时,不只关心模型有多聪明,还关心它会不会突然乱码、会不会重复、会不会在关键任务里掉链子。
AI行业下一阶段的竞争,可能不是谁喊得最大声,而是谁能把这些看不见的底层问题,一个一个修干净。

愿意公开踩坑经历的公司,反而可能跑得更远。
最后说一句
这次GLM-5“降智”事件,最有意思的地方在于,它让外界看到:大模型不是一个孤零零的聊天框。
它背后是一整套复杂系统。
模型、GPU、缓存、服务器、调度、监控,只要其中一个环节没配合好,用户看到的就是一句话:
“这个AI怎么变傻了?”
但工程师看到的是另一句话:
不是AI变傻了,是系统终于被真实使用量压出了问题。
这可能才是国产大模型真正走向生产级应用的开始。
盈富忧配提示:文章来自网络,不代表本站观点。



沪深京行情 实时轮播
热点资讯
